# 圈复杂度
# 定义
怎么才能写出浅显易懂的代码就不得不提软件工程质量度量方法中一个重要的概念——圈复杂度。
圈复杂度(Cyclomatic complexity,简写 CC)也称为条件复杂度,是一种代码复杂度的衡量标准。由托马斯·J·麦凯布(Thomas J. McCabe, Sr.)于 1976 年提出,用来表示程序的复杂度。它可以用来衡量一个模块判定结构的复杂程度,数量上表现为独立现行路径条数,也可理解为覆盖所有的可能情况最少使用的测试用例数。 简称 CC 。其符号为 VG 或是 M 。
圈复杂度大说明程序代码的判断逻辑复杂,可能质量低且难于测试和维护。有研究表明复杂度和出现缺陷的数量存在强相关性,表明了越复杂的代码越可能会出错。
# 衡量标准
代码复杂度低,代码不一定好,但代码复杂度高,代码一定不好
| 圈复杂度 | 代码状况 | 可测性 | 维护成本 |
|---|---|---|---|
| 1 - 10 | 清晰、结构化 | 高 | 低 |
| 10 - 20 | 复杂 | 中 | 中 |
| 20 - 30 | 非常复杂 | 低 | 高 |
| >30 | 不可读 | 不可测 | 非常高 |
# 计算方法
圈复杂度衡量的是程序中线性独立路径的数量。
例如:如果程序中不包含控制、判断、条件语句,那么复杂度就是 1,因为整个程序只有一条执行路径;
如果程序包含一条 IF 语句,那么就会有两条路径来执行完整个程序,所以这时候的复杂度就是 2;
两个嵌套的 IF 语句,或者包含两个判断条件的一个 IF 语句,复杂度就是 2 * 2 = 4。
更加具体的情况看下图:
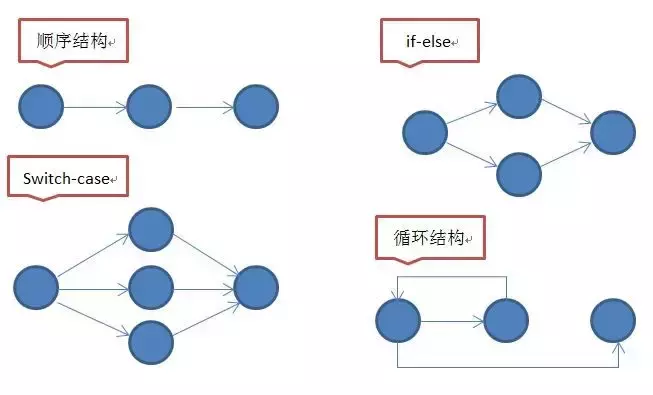
# 控制流程图
控制流程图,是一个过程或程序的抽象表现,是用在编译器中的一个抽象数据结构,由编译器在内部维护,代表了一个程序执行过程中会遍历到的所有路径。它用图的形式表示一个过程内所有基本块执行的可能流向, 也能反映一个过程的实时执行过程。
下面是一些常见的控制流程:
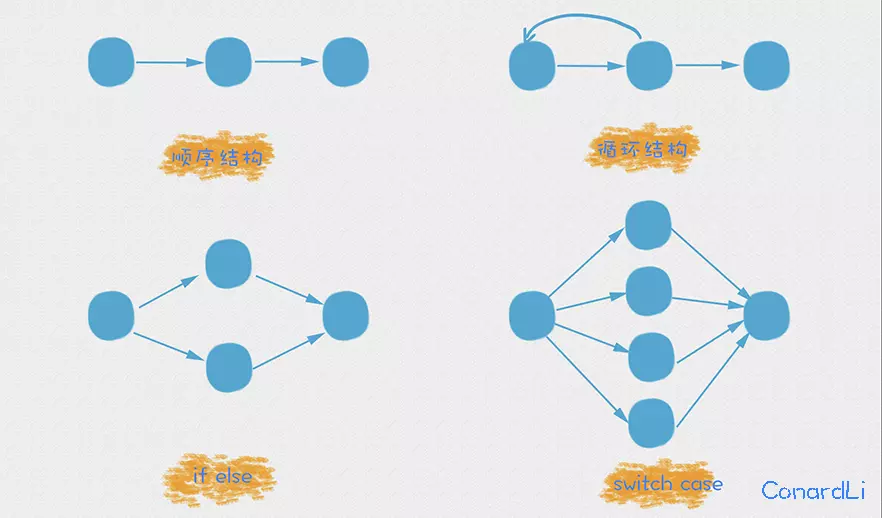
# 节点判定法
有一个简单的计算方法,圈复杂度实际上就是等于判定节点的数量再加上 1。向上面提到的:if else 、switch case 、 for循环、三元运算符等等,都属于一个判定节点 , 例如下面的代码 :
function testComplexity(*param*) {
let result = 1;
if (param > 0) {
result--;
}
for (let i = 0; i < 10; i++) {
result += Math.random();
}
switch (parseInt(result)) {
case 1:
result += 20;
break;
case 2:
result += 30;
break;
default:
result += 10;
break;
}
return result > 20 ? result : result;
}
上面的代码中一共有1个if语句,一个for循环,两个case语句,一个三元运算符,所以代码复杂度为 1+2+1+1+1=6。另外,需要注意的是 || 和 && 语句也会被算作一个判定节点,例如下面代码的代码复杂为3:
function testComplexity(*param*) {
let result = 1;
if (param > 0 && param < 10) {
result--;
}
return result;
}
# 点边计算法
M = E − N + 2P
- E: 控制流图中 边 的 数量
- N:控制流图中 节点 的 数量
- P:独立组件的数目
前两个,边和节点都是数据结构途中最基本的概念:
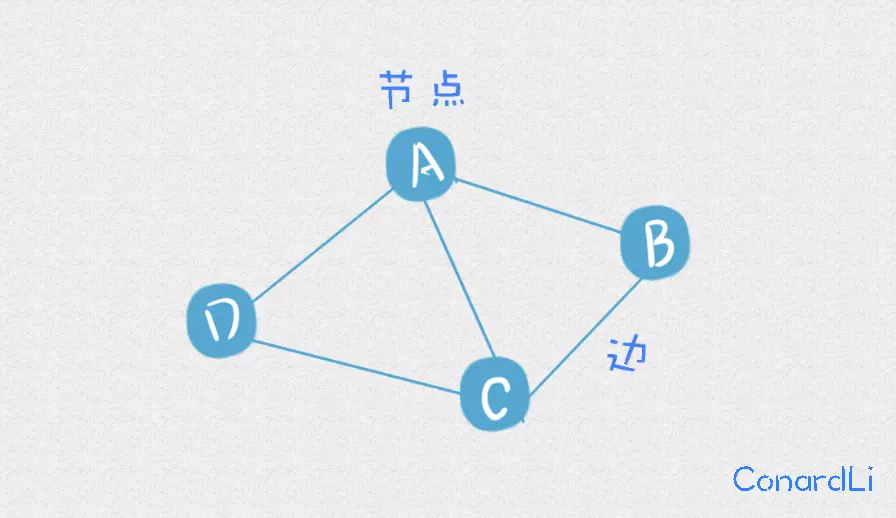
P 代表图中独立组件的数目,独立组件是什么意思呢?来看看下面两个图,左侧为连通图,右侧为非连通图:
- 连通图: 对于图中任意两个顶点都是连通的
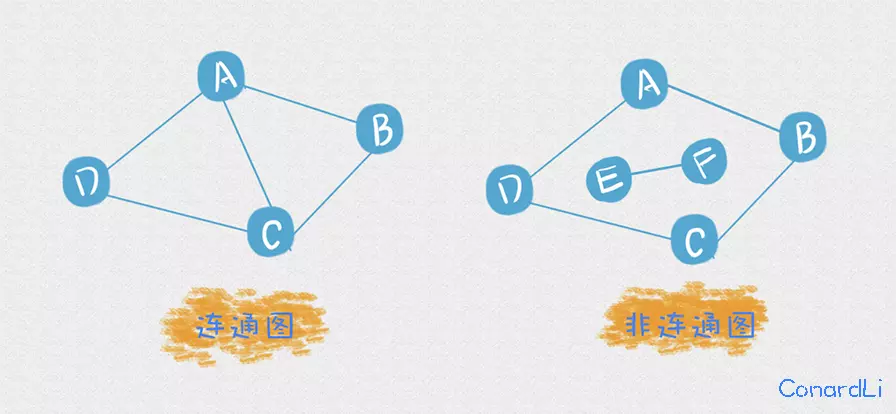
一个连通图即为图中的一个独立组件,所以左侧图中独立组件的数目为 1,右侧则有两个独立组件。
对于我们的代码转化而来的控制流程图,正常情况下所有节点都应该是连通的,除非你在某些节点之前执行了 return,显然这样的代码是错误的。所以每个程序流程图的独立组件的数目都为 1,所以上面的公式还可以简化为 M = E − N + 2 。
# 降低代码的圈复杂度
我们可以通过一些代码重构手段来降低代码的圈复杂度。
重构需谨慎,示例代码仅仅代表一种思想,实际代码要远远比示例代码复杂的多。
# 抽象配置
通过抽象配置将复杂的逻辑判断进行简化。例如下面的代码,根据用户的选择项执行相应的操作,重构后降低了代码复杂度,并且如果之后有新的选项,直接加入配置即可,而不需要再去深入代码逻辑中进行改动:

# 单一职责 - 提炼函数
单一职责原则(SRP):每个类都应该有一个单一的功能,一个类应该只有一个发生变化的原因。
在 JavaScript 中,需要用到的类的场景并不太多,单一职责原则则是更多地运用在对象或者方法级别上面。
函数应该做一件事,做好这件事,只做这一件事。 — 代码整洁之道
关键是如何定义这 “一件事” ,如何将代码中的逻辑进行抽象,有效的提炼函数有利于降低代码复杂度和降低维护成本。

# 使用 break 和 return 代替控制标记
我们经常会使用一个控制标记来标示当前程序运行到某一状态,很多场景下,使用 break 和 return 可以代替这些标记并降低代码复杂度。
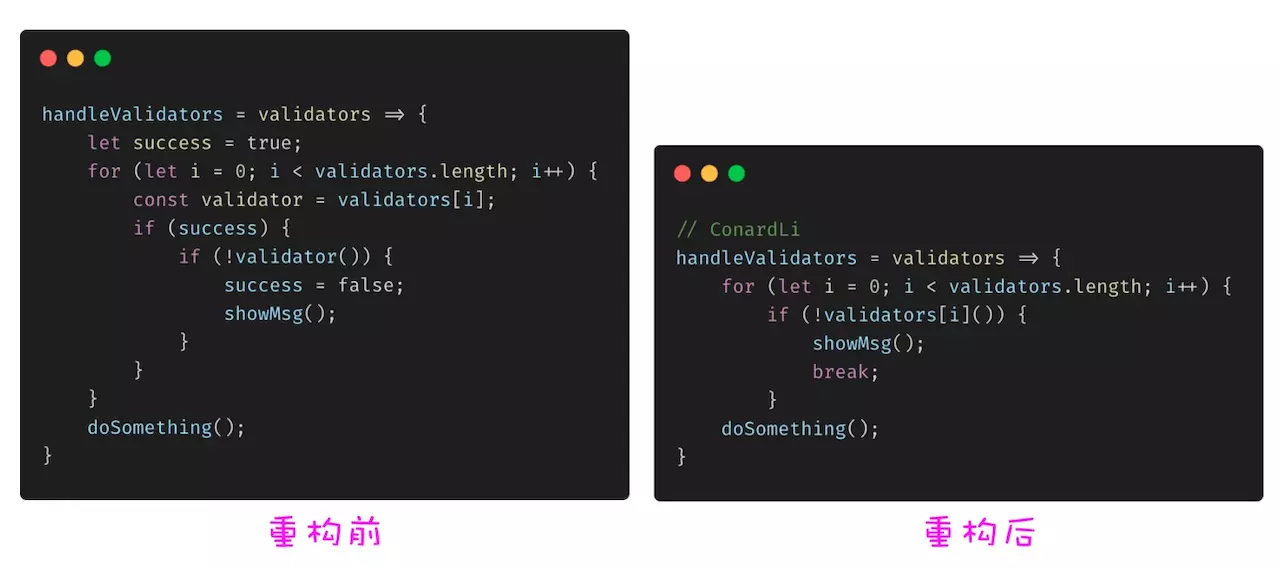
# 用函数取代参数
setField 和 getField 函数就是典型的函数取代参数,如果么有 setField、getField 函数,我们可能需要一个很复杂的 setValue、getValue 来完成属性赋值操作:

# 简化条件判断 - 逆向条件
某些复杂的条件判断可能逆向思考后会变的更简单。

# 简化条件判断 -合并条件
将复杂冗余的条件判断进行合并。

# 简化条件判断 - 提取条件
将复杂难懂的条件进行语义化提取。
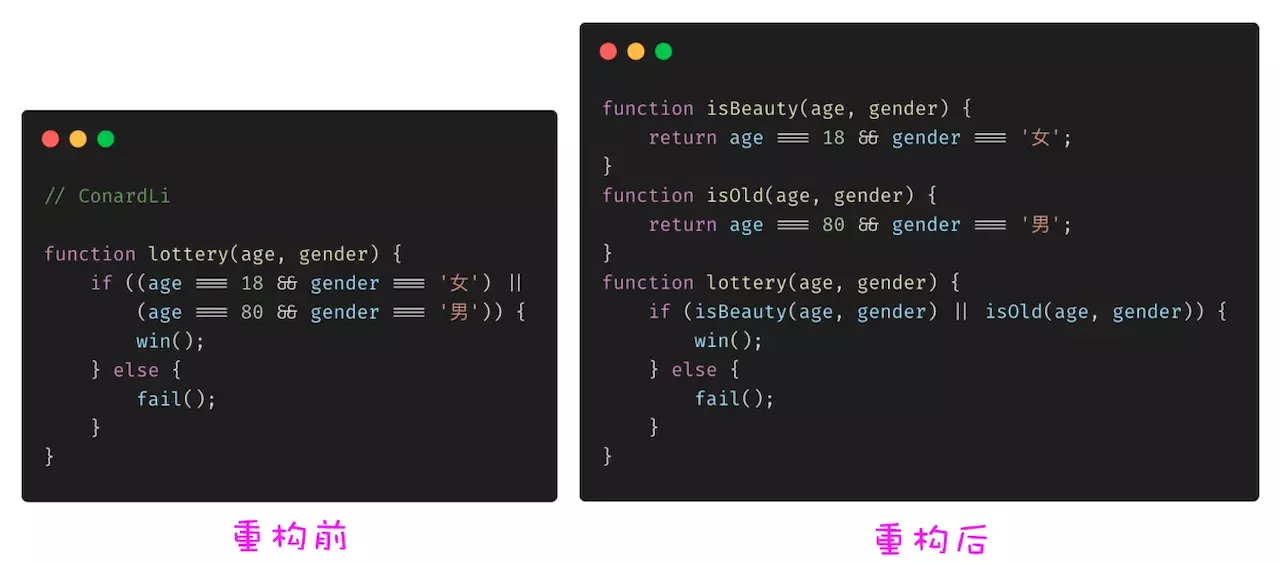
# 圈复杂度检测方法
# eslint 规则
eslint提供了检测代码圈复杂度的rules:
我们将开启 rules 中的 complexity 规则,并将圈复杂度大于 0 的代码的 rule severity 设置为 warn 或 error 。
rules: {
complexity: ["warn", { max: 0 }];
}
这样 eslint 就会自动检测出所有函数的代码复杂度,并输出一个类似下面的 message。
Method 'testFunc' has a complexity of 12. Maximum allowed is 0
Async function has a complexity of 6. Maximum allowed is 0.
...
# CLIEngine
我们可以借助 eslint 的 CLIEngine ,在本地使用自定义的 eslint 规则扫描代码,并获取扫描结果输出。
初始化 CLIEngine :
const eslint = require("eslint");
const { CLIEngine } = eslint;
const cli = new CLIEngine({
parserOptions: {
ecmaVersion: 2018,
},
rules: {
complexity: ["error", { max: 0 }],
},
});
使用 executeOnFiles 对指定文件进行扫描,并获取结果,过滤出所有 complexity 的 message 信息。
const reports = cli.executeOnFiles(["."]).results;
for (let i = 0; i < reports.length; i++) {
const { messages } = reports[i];
for (let j = 0; j < messages.length; j++) {
const { message, ruleId } = messages[j];
if (ruleId === "complexity") {
console.log(message);
}
}
}
# 提取 message
通过 eslint 的检测结果将有用的信息提取出来,先测试几个不同类型的函数,看看 eslint 的检测结果:
function func1() {
console.log(1);
}
const func2 = () => {
console.log(2);
};
class TestClass {
func3() {
console.log(3);
}
}
async function func4() {
console.log(1);
}
执行结果:
Function 'func1' has a complexity of 1. Maximum allowed is 0.
Arrow function has a complexity of 1. Maximum allowed is 0.
Method 'func3' has a complexity of 1. Maximum allowed is 0.
Async function 'func4' has a complexity of 1. Maximum allowed is 0.
可以发现,除了前面的函数类型,以及后面的复杂度,其他都是相同的。
函数类型:
Function:普通函数Arrow function: 箭头函数Method: 类方法Async function: 异步函数
截取方法类型:
const REG_FUNC_TYPE = /^(Method |Async function |Arrow function |Function )/g;
function getFunctionType(message) {
let hasFuncType = REG_FUNC_TYPE.test(message);
return hasFuncType && RegExp.$1;
}
将有用的部分提取出来:
const MESSAGE_PREFIX = "Maximum allowed is 1.";
const MESSAGE_SUFFIX = "has a complexity of ";
function getMain(message) {
return message.replace(MESSAGE_PREFIX, "").replace(MESSAGE_SUFFIX, "");
}
提取方法名称:
function getFunctionName(message) {
const main = getMain(message);
let test = /'([a-zA-Z0-9_$]+)'/g.test(main);
return test ? RegExp.$1 : "*";
}
截取代码复杂度:
function getComplexity(message) {
const main = getMain(message);
/(\d+)\./g.test(main);
return +RegExp.$1;
}
除了 message ,还有其他的有用信息:
- 函数位置:获取
messages中的line、column即函数的行、列位置 - 当前文件名称:
reports结果中可以获取当前扫描文件的绝对路径filePath,通过下面的操作获取真实文件名:
filePath.replace(process.cwd(), '').trim()
- 复杂度等级,根据函数的复杂度等级给出重构建议:
| 圈复杂度 | 代码状况 | 可测性 | 维护成本 |
|---|---|---|---|
| 1 - 10 | 清晰、结构化 | 高 | 低 |
| 10 - 20 | 复杂 | 中 | 中 |
| 20 - 30 | 非常复杂 | 低 | 高 |
| >30 | 不可读 | 不可测 | 非常高 |
| 圈复杂度 | 代码状况 |
|---|---|
| 1 - 10 | 无需重构 |
| 11 - 15 | 建议重构 |
| >15 | 强烈建议重构 |
# 架构设计
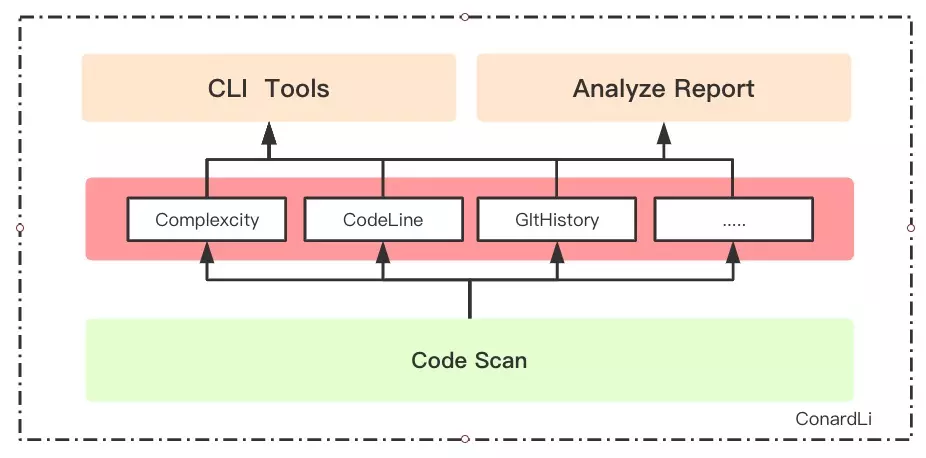
将代码复杂度检测封装成基础包,根据自定义配置输出检测数据,供其他应用调用。
上面的展示了使用 eslint 获取代码复杂度的思路,下面我们要把它封装为一个通用的工具,考虑到工具可能在不同场景下使用,例如:网页版的分析报告、cli 版的命令行工具,我们把通用的能力抽象出来以 npm包 的形式供其他应用使用。
在计算项目代码复杂度之前,我们首先要具备一项基础能力,代码扫描,即我们要知道我们要对项目里的哪些文件做分析,首先 eslint 是具备这样的能力的,我们也可以直接用 glob 来遍历文件。但是他们都有一个缺点,就是 ignore 规则是不同的,这对于用户来讲是有一定学习成本的,因此我这里把手动封装代码扫描,使用通用的 npm ignore 规则,这样代码扫描就可以直接使用 .gitignore这样的配置文件。另外,代码扫描作为代码分析的基础能力,其他代码分析也是可以公用的。
- 基础能力
- 代码扫描能力
- 复杂度检测能力
- ...
- 应用
- 命令行工具
- 代码分析报告
- ...
Gitment →